Les plateformes technologiques et les référentiels publicitaires à l'épreuve de la transparence et de la responsabilité
Le rapport "Full Disclosure" de la fondation Mozilla évalue la transparence et la responsabilité des géants de la tech et des référentiels publicitaires face aux défis sociétaux actuels.
 Crédit image : Fondation Mozilla
Crédit image : Fondation Mozilla
Les plateformes technologiques sont devenues un élément essentiel de notre vie quotidienne, mais leur impact sur notre société est de plus en plus controversé. Les préoccupations concernant la désinformation, la vie privée et la sécurité ont conduit à des appels à une plus grande transparence et responsabilité de la part de ces entreprises. Dans ce contexte, Ranking Digital Rights (RDR), une organisation à but non lucratif, a publié un rapport intitulé "Full Disclosure: Stress Testing Tech Platforms & Ad Repositories", qui évalue la transparence et la responsabilité des plateformes technologiques et des référentiels publicitaires.
Le rapport de RDR se concentre sur les politiques et les pratiques de huit grandes plateformes technologiques - Facebook, Google, Twitter, Microsoft, Apple, Amazon, Tencent et Baidu - ainsi que sur les référentiels publicitaires utilisés par ces entreprises pour cibler les publicités en ligne. Les auteurs du rapport ont évalué la transparence et la responsabilité de ces entreprises en utilisant une méthodologie basée sur 35 indicateurs, regroupés en cinq catégories: gouvernance, liberté d'expression, vie privée, sécurité et responsabilité.
Les résultats du rapport montrent que, bien que certaines entreprises aient fait des progrès en matière de transparence et de responsabilité, il reste encore beaucoup à faire. Par exemple, le rapport note que Facebook a amélioré sa transparence en matière de publicité politique, mais que l'entreprise doit encore faire davantage pour lutter contre la désinformation et les discours haineux. De même, le rapport note que Google a pris des mesures pour améliorer la transparence de son référentiel publicitaire, mais que l'entreprise doit encore faire davantage pour protéger la vie privée des utilisateurs.
Le rapport souligne également l'importance de la transparence et de la responsabilité des référentiels publicitaires, qui sont souvent utilisés pour cibler les publicités en ligne en fonction des données personnelles des utilisateurs. Le rapport note que de nombreux référentiels publicitaires ne sont pas suffisamment transparents quant aux données qu'ils collectent et à la manière dont ils les utilisent. En outre, le rapport souligne que les référentiels publicitaires doivent être plus responsables en matière de protection de la vie privée et de sécurité des utilisateurs.
Le rapport de RDR conclut que la transparence et la responsabilité des plateformes technologiques et des référentiels publicitaires sont essentielles pour protéger les droits de l'homme et la démocratie. Les auteurs du rapport appellent les entreprises à prendre des mesures concrètes pour améliorer leur transparence et leur responsabilité, notamment en publiant des rapports réguliers sur leur impact social et environnemental, en renforçant leur gouvernance et en améliorant leur engagement avec les parties prenantes.
En fin de compte, le rapport de RDR montre que la transparence et la responsabilité des plateformes technologiques et des référentiels publicitaires sont des enjeux cruciaux pour notre société. Il est essentiel que ces entreprises prennent des mesures concrètes pour améliorer leur transparence et leur responsabilité, afin de protéger les droits de l'homme et la démocratie. Les consommateurs, les régulateurs et les investisseurs doivent également exiger une plus grande transparence et responsabilité de la part de ces entreprises, afin de garantir que les plateformes technologiques et les référentiels publicitaires soient utilisés de manière responsable et éthique.
Source :
Fondation Mozilla
Le rapport Full Disclosure
Publié le par Technifree
En parler sur le forum
Remettre l'humain et le droit au coeur des services publics dématérialisés
La protection des données personnelles, un enjeu majeur face aux cyberattaques (utopie quand tu nous tiens ...).
 Crédit image : collectifchangerdecap
Crédit image : collectifchangerdecap
Depuis 2019, le collectif Changer de Cap rassemble des militants et des associations autour des questions de justice sociale et environnementale, de la défense des services publics et de la promotion de la démocratie réelle. Il constitue une plateforme d’appui et de mise en réseau de collectifs citoyens et autres acteurs locaux en mutualisant les actions porteuses d’alternatives, les informations et les réflexions.
Les membres du collectif travaillent ensemble malgré une grande diversité d’opinions politiques, syndicales ou citoyennes, grâce à la conviction que la mobilisation doit s’enraciner dans la diversité et la richesse des opinions et des actions citoyennes porteuses d’alternatives, dans les luttes et dans une réflexion commune autour de questions concrètes.
Depuis fin 2021, Changer de Cap a ouvert ses actions et réflexions aux conséquences de la dématérialisation des services publics, notamment au sein des CAF. Le recueil de témoignages, un travail de recherche et de réflexion, des rencontres et des forums ont débouché sur le constat de zones de non-droit et d’une maltraitance institutionnelle des plus précaires, ainsi que sur une série de propositions visant à « Remettre l’humain et le droit au coeur de l’action des CAF ».
La mise en lumière d’actions porteuses d’alternatives via le site internet, de luttes victorieuses dans la Lettre mensuelle du collectif, tout comme la mise en perspective politique, font partie de l’ADN de Changer de Cap depuis ses débuts.
Dans le contexte de la dématérialisation des services publics, la protection des données personnelles est devenue un enjeu majeur. En effet, l’État se sert de nos données personnelles et doit les protéger et respecter nos droits. Récemment, une cyberattaque a visé un service public et a entraîné l’exfiltration des données personnelles de 43 millions de personnes, y compris celles d’anciens demandeurs d’emploi jusqu’à 20 ans en arrière. Cette cyberattaque interroge sur la sécurité de nos données personnelles au sein même des administrations qui savent tout de nous grâce à la collecte, au traitement et au partage de ces mêmes données.
La liste des cyberattaques s’allonge et le principal risque est l’usurpation d’identité, avec son cortège de galères. Les administrations doivent donc prévenir toute violation de données personnelles et mettre en place des processus de sécurité dignes d’un organisme étatique. De plus, la conservation aussi longuement des données personnelles interroge vis-à-vis d’un principe de base du RGPD : la stricte limitation de la durée de conservation des données personnelles.
Face à cette situation, Changer de Cap exige des garanties suffisantes de protection de nos données personnelles. L’arrestation de quelques hackers ne suffit pas. Il est nécessaire que toute la lumière soit faite sur les conditions qui ont permis cette fuite de données et sur la responsabilité de France Travail et de ses prestataires en cybersécurité. Plus généralement, les administrations doivent fournir des garanties suffisantes de protection des données personnelles aux administrés. La question de la cybersécurité doit être prise en compte de manière sérieuse dans la mise en œuvre de ces politiques publiques.
Si vous pensez avoir été victime de la fuite de données, Changer de Cap vous encourage à porter plainte via le formulaire de Lettre de plainte en ligne et à indiquer que des poursuites soient entamées non seulement sur les fondements annoncés par le parquet, mais aussi sur le fondement de l’article 226-17 du Code pénal contre toute personne identifiée par l’enquête. Dans tous les cas, protégez-vous en prenant une capture d’écran du message sur votre espace France Travail et en étant particulièrement vigilant aux emails, appels et SMS dans les prochaines semaines. Si vous êtes concerné et intéressé pour aller plus loin dans cette démarche de plainte contre France Travail, vous pouvez contacter le groupe de travail numérique de Changer de Cap, sur leur site internet.
Source :
Collectif Changer de Cap
Publié le par Technifree
En parler sur le forum
Les jeunes Français et la lecture : un attachement réel, mais une pratique en déclin face aux réseaux sociaux
Une étude du Centre national du livre (CNL) met en lumière les défis auxquels font face les jeunes lecteurs dans un monde dominé par les écrans et les réseaux sociaux.
 Crédit image : CNL
Crédit image : CNL
Le Centre national du livre (CNL) a récemment présenté une étude consacrée aux jeunes Français et à leur pratique de la lecture. Les résultats de cette étude montrent un attachement réel des jeunes à la lecture, mais aussi une baisse de leur pratique, notamment chez les 16-19 ans. Les réseaux sociaux et les écrans sont pointés du doigt comme étant les principaux responsables de cette situation.
Un attachement réel à la lecture, mais une baisse de la pratique
L'étude menée par Ipsos et le CNL a interrogé 1500 personnes âgées de 7 à 19 ans. Les résultats montrent que les jeunes lisent moins qu'il y a deux ans, que ce soit pour l'école ou pour le plaisir. En effet, ils ne sont plus que 84 % à lire pour l'école et 81 % à lire pour le plaisir, contre respectivement 86 % et 83 % en 2022.
Cette baisse, bien que légère, inquiète Régine Hatchondo, présidente du Centre national du livre. Selon elle, ces résultats sont préoccupants non seulement pour la chaîne du livre, mais aussi pour la société dans son ensemble. Elle souligne que le développement de l'esprit critique, de l'altérité, de l'imaginaire, de l'enrichissement du vocabulaire et de la capacité d'exprimer ses émotions passe par la langue et la lecture.
Les réseaux sociaux, un défi de taille
L'étude met en évidence un décrochage important chez les 16-19 ans. Un tiers de ces jeunes ne lirait pas du tout pour ses loisirs, et la part de ceux qui lisent a reculé de 12 points en deux ans. De plus, les jeunes consacrent en moyenne 19 minutes par jour à la lecture, contre 3h11 aux écrans.
Régine Hatchondo pointe du doigt les réseaux sociaux, qui ont réussi à rendre totalement dépendants les enfants, les adolescents et les adultes aux algorithmes. Cette dépendance entraîne des problèmes de concentration et des troubles de l'anxiété, particulièrement chez les 16-19 ans.
La lecture multitâche, une nouvelle tendance
L'étude révèle également que 48 % des jeunes font souvent autre chose en même temps qu'ils lisent. Près d'un jeune lecteur sur deux (69 % des 16-19 ans) fait autre chose pendant ses lectures, et ce encore plus fortement qu'auparavant.
L'éducation, un espoir pour la lecture
Face à ce constat, l'éducation semble être un recours pour promouvoir la lecture auprès des jeunes. Selon Étienne Mercier, directeur du pôle Opinion et Santé de l'Institut Ipsos, l'Éducation nationale fait plutôt bien son travail jusqu'à 16 ans. Cependant, à partir de cet âge, les enseignants perdent la bataille en partie.
Régine Hatchondo invite donc à une multiplication d'actions publiques en faveur de la lecture, comme le partenariat du CNL avec l'Éducation nationale autour du quart d'heure de lecture et le Pass Culture. Elle exhorte également les adultes à endosser des rôles de modèles et à rompre avec leur propre consommation des écrans.
L'étude du CNL montre que les jeunes Français sont toujours attachés à la lecture, mais que leur pratique est en déclin face aux réseaux sociaux et aux écrans. Pour assurer de futures générations de lecteurs et lectrices, il est essentiel de promouvoir la lecture dès la naissance et de sensibiliser les adultes à leur rôle de modèles.
Sources multiples :
Actualitte.com
CNL
Publié le par Technifree
En parler sur le forum
Le projet de loi pour sécuriser internet (SREN) définitivement adopté : un pas vers une régulation accrue de l'espace numérique malgré les réserves
Le projet de loi visant à sécuriser et réguler l'espace numérique (SREN) a été définitivement adopté, malgré des réserves émises par plusieurs groupes concernant la menace potentielle sur les libertés publiques. Le texte a été approuvé par 134 députés et 75 ont voté contre, provenant des rangs du RN et des quatre groupes de gauche. La France insoumise a annoncé un recours devant le Conseil constitutionnel.
Ce projet de loi vise à lutter contre divers fléaux en ligne tels que le cyberharcèlement, les arnaques sur internet, les propos haineux et l'accessibilité des sites pornographiques aux mineurs. Il s'appuie sur les règlements européens sur les services numériques et les marchés numériques pour apporter des réponses à ces problèmes.
Cependant, certaines dispositions du texte ont suscité des inquiétudes. Par exemple, un délit d'outrage en ligne a été créé, passible d'une amende forfaitaire délictuelle de 300 euros. Ce délit permettra de sanctionner la diffusion en ligne de tout contenu portant atteinte à la dignité d'une personne ou présentant un caractère injurieux, dégradant, humiliant ou créant une situation intimidante, hostile ou offensante. Cette disposition a été critiquée par l'association de défense des libertés numériques La Quadrature du net et le RN, qui estiment qu'elle est floue et déroge à la loi de 1881.
La France insoumise s'est opposée au projet de loi, le qualifiant de dangereux pour les droits fondamentaux. La députée Sophia Chikirou a soulevé des questions sur l'impact potentiel de ce texte sur la liberté d'expression en ligne.
Le projet de loi instaure également un nouveau cadre légal pour les "Jonum", les jeux à objets numériques monétisables, qui se situent à la frontière entre jeux vidéo et jeux d'argent. Ce cadre autorisera à titre dérogatoire les gains en cryptomonnaie en les encadrant. La France insoumise a critiqué cette réglementation, l'accusant de créer une nouvelle drogue pour de nombreux Français dans le seul but de créer une nouvelle source de revenus pour des start-ups.
En ce qui concerne la réglementation des plateformes de vidéos pornographiques, plusieurs députés et associations féministes et de protection des mineurs ont déploré des ambitions réduites. Ils ont exprimé des inquiétudes quant à l'efficacité du pouvoir de régulation de l'Arcom sur les sites qui n'empêchent pas les mineurs d'accéder à leur contenu, en particulier ceux situés en Europe.
Le texte prévoit également la création d'un filtre anti-arnaques gratuit, le bannissement des cyberharceleurs, la création d'une identité numérique d'ici 2027 et le blocage administratif des sites pornographiques et des médias de propagande.
En résumé, le projet de loi SREN a pour objectif de sécuriser et réguler l'espace numérique en luttant contre divers fléaux en ligne. Cependant, certaines dispositions ont suscité des inquiétudes quant à leur impact sur les libertés publiques et leur efficacité. Le texte a été définitivement adopté, mais fera l'objet d'un recours devant le Conseil constitutionnel.
Sources multiples :
d-rating
CBNews
Assemblée Nationale
Vie Publique
Galaxie Sénat
Publié le par Technifree
En parler sur le forum
Refuser les cookies : l'option décorative qui adore collecter vos données !
Le débat sur la vie privée en ligne est plus pertinent que jamais. Alors que nous naviguons sur internet, des décisions importantes concernant notre vie privée sont prises à notre insu. Une étude récente, réalisée par des chercheurs de l'Université d'Amsterdam en collaboration avec l'ETH Zurich, jette une lumière crue sur l'efficacité réelle du système de consentement aux cookies, révélant une réalité troublante : la majorité des sites web européens collectent des données personnelles sans le consentement réel des utilisateurs.
 Crédit image : DALL.E
Crédit image : DALL.E
Les cookies, de petits fichiers stockés sur nos appareils par les sites web que nous visitons, sont au cœur de cette problématique. Ils jouent un rôle essentiel dans notre expérience en ligne, mémorisant nos préférences et nos identifiants. Cependant, certains cookies, notamment les cookies traceurs, posent un risque pour notre vie privée en suivant notre activité en ligne pour cibler des publicités basées sur nos intérêts.
L'étude et ses révélations
L'outil développé par les chercheurs a analysé 97 000 sites web, permettant une comparaison directe entre les pratiques déclarées par les sites et leurs actions réelles. Le constat est alarmant : la majorité des sites web étudiés enfreignent une ou plusieurs normes de protection de la vie privée.
Nous constatons notamment que 65,4 % des sites web offrant une option de refus des cookies sont susceptibles de collecter des données sur les utilisateurs en dépit d'un consentement explicite négatif.
Violations naïves et délibérées
L'étude catégorise les infractions en deux types : les violations naïves, comme l'absence d'option de refus des cookies, et les violations délibérées, où les sites installent des cookies traceurs même lorsque l'utilisateur les refuse. Ces pratiques non seulement violent la réglementation en vigueur mais sapent également la confiance des utilisateurs envers le site web.
Les "dark patterns" : une tactique de tromperie
Une technique particulièrement inquiétante relevée par l'étude est l'utilisation des "dark patterns". Ces méthodes de conception visent à manipuler les choix des utilisateurs, rendant le bouton "accepter" plus visible et attrayant par rapport à l'option "refuser", souvent minimisée ou rendue difficile à trouver.
Un système de consentement défaillant
L'étude conclut sur une note critique envers le système actuel de consentement aux cookies, jugé inefficace. Elle pointe du doigt non seulement le manque de connaissances techniques et juridiques des petits sites web mais aussi l'attitude de certains grands acteurs qui choisissent d'ignorer ou de contourner les règles établies.
Actions et réactions réglementaires
Face à cette situation, les autorités comme la CNIL en France ont pris des mesures, prononçant près de 100 actions correctives depuis la date limite de mise en conformité aux nouvelles règles sur les cookies. Cependant, l'efficacité de ces interventions reste à démontrer, soulignant le besoin d'une réforme plus profonde du système de consentement.
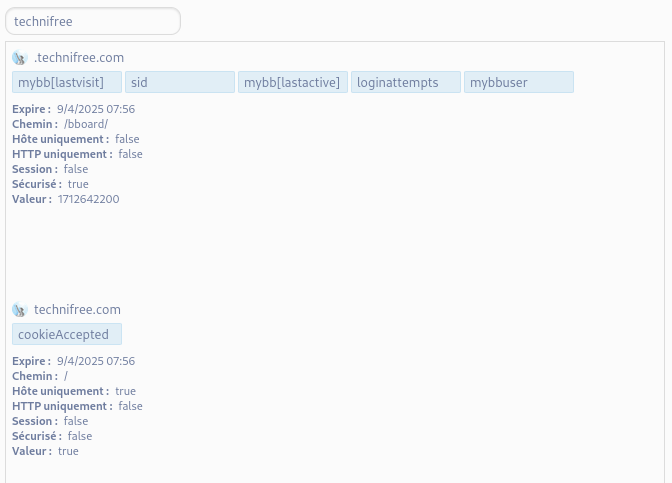 Cookies de technifree
Cookies de technifree
Cette étude révèle une réalité troublante sur le web européen, où le respect de la vie privée des internautes est souvent relégué au second plan. Elle appelle à une réflexion urgente sur les mécanismes de consentement et sur la manière dont nous, en tant que société, valorisons et protégeons notre vie privée en ligne. Le chemin vers un internet respectueux de la vie privée est semé d'embûches, mais c'est une quête qui mérite notre attention et notre engagement.
Sources multiples :
Tom's Guide
Usenix
Publié le par Technifree
En parler sur le forum
La CNIL : un rôle clé dans le développement éthique et responsable de l'Intelligence Artificielle
La Commission Nationale de l'Informatique et des Libertés (CNIL), autorité administrative indépendante française chargée de veiller à la protection des données personnelles, se positionne comme un acteur majeur dans le développement éthique et responsable de l'Intelligence Artificielle (IA). À travers deux articles publiés en octobre 2023 et avril 2024, la CNIL dévoile ses premières réponses et recommandations pour une IA innovante et respectueuse de la vie privée.
Une IA innovante et respectueuse des personnes : l'engagement de la CNIL
La CNIL, consciente des opportunités technologiques offertes par l'IA dans divers domaines tels que la santé, les services publics ou la productivité des entreprises, souhaite accompagner les acteurs innovants tout en garantissant la protection des libertés individuelles. Cependant, l'entraînement des algorithmes consomme beaucoup de données, notamment personnelles, et peut dans certains cas porter atteinte aux droits des personnes.
Face à ces défis, la CNIL promeut une innovation responsable et a créé en janvier 2023 un service dédié à l'IA. Elle a également lancé un plan d'action visant à clarifier les règles et à soutenir l'innovation dans ce domaine. Deux programmes d'accompagnement ont été mis en place pour accompagner des acteurs français : un bac à sable pour trois projets utilisant l'IA au bénéfice des services publics et un dispositif d'accompagnement renforcé pour trois entreprises innovantes de taille intermédiaire.
La sécurité juridique : un enjeu majeur pour les acteurs de l'IA
Après avoir rencontré les principaux acteurs français de l'IA et lancé un appel à contributions sur la constitution de bases de données, la CNIL publie une première série de lignes directrices pour un usage de l'IA respectueux des données personnelles. Cette initiative vise à répondre au fort besoin de sécurité juridique exprimé par les acteurs du secteur.
Le RGPD : un cadre innovant et protecteur pour l'IA
La CNIL réaffirme la compatibilité des recherches et développements en IA avec le Règlement Général sur la Protection des Données (RGPD), à condition de respecter certaines conditions et de ne pas franchir certaines lignes rouges. Elle précise l'application des principes de finalité, de minimisation, de conservation limitée et de réutilisation restreinte dans le contexte de l'IA.
Les premières recommandations de la CNIL pour un usage respectueux des données personnelles
À l'issue d'une consultation publique, la CNIL publie en avril 2024 ses premières recommandations sur le développement des systèmes d'IA. Ces recommandations, élaborées en concertation avec les acteurs de l'IA, visent à aider les professionnels à concilier innovation et respect des droits des personnes. Elles abordent des points clés tels que la détermination du régime juridique applicable, la définition d'une finalité, la qualification juridique des acteurs, ou encore la réalisation d'une analyse d'impact si nécessaire.
La CNIL prévoit de compléter ces premières recommandations par d'autres fiches portant notamment sur la base légale de l'intérêt légitime, la gestion des droits, l'information des personnes concernées, ou encore la sécurité lors de la phase de développement. Ces travaux seront également soumis à consultation publique.
La CNIL joue un rôle essentiel dans l'encadrement du développement de l'IA, en veillant à concilier innovation et respect de la vie privée. Ses recommandations et lignes directrices permettent aux acteurs de l'écosystème IA de disposer d'éléments clairs et pratiques pour éclairer leurs décisions stratégiques de développement ou d'utilisation de l'IA.
Sources multiples :
CNIL (2024)
CNIL (2023)
Publié le par Technifree
En parler sur le forum
Quarante Deux
Le chiffre 42 a acquis une notoriété culturelle et philosophique considérable depuis sa première mention dans le roman de science-fiction "Le Guide du voyageur galactique" (The Hitchhiker's Guide to the Galaxy) de Douglas Adams. Ce nombre, présenté comme la réponse ultime à "la grande question sur la vie, l'univers et tout le reste", a transcendé les frontières du livre pour devenir un symbole largement reconnu dans de nombreux domaines, allant de la science à la culture populaire. Cet article explore la genèse de cette curieuse réponse, son impact culturel et philosophique, ainsi que les différentes manières dont il est utilisé aujourd'hui.
 Crédit image : DALL.E
Crédit image : DALL.E
Genèse dans "Le Guide du voyageur galactique"
Dans le roman de Douglas Adams, le chiffre 42 est la réponse donnée par un superordinateur nommé Deep Thought après sept millions et demi d'années de calcul pour trouver la réponse à la grande question de la vie, l'univers et tout le reste. Cependant, il est révélé que personne ne connaît réellement la question. Ce paradoxe crée une situation absurde mais profondément significative, reflétant la quête humaine incessante de sens dans un univers peut-être indifférent à nos interrogations.
La symbolique et l'impact culturel
Le choix de Douglas Adams du nombre 42 comme réponse universelle est souvent perçu comme une blague arbitraire, soulignant l'absurdité de chercher une réponse simple à des questions complexes. Adams lui-même a mentionné dans plusieurs interviews que le choix du nombre 42 était aléatoire, privilégiant l'humour et l'absurdité de la situation. Néanmoins, cela n'a pas empêché les fans et les penseurs de spéculer sur les significations cachées, allant de la théorie que 42 est un nombre significatif dans différentes traditions mystiques et scientifiques, à des interprétations plus ludiques et inventives.
Utilisations diverses de 42
• Dans la culture populaire : Le chiffre 42 est devenu un symbole reconnu par les fans de science-fiction, souvent utilisé pour faire référence, avec humour ou sérieux, à la quête de sens dans la vie. Il apparaît dans divers médias, y compris des films, des émissions de télévision, des jeux vidéo, et même dans des chansons. Son omniprésence sert de clin d'œil partagé par ceux qui connaissent le roman de Adams.
• En science et technologie : Curieusement, 42 a trouvé une place dans le monde de la science et de la technologie, où il est parfois utilisé dans des exemples de programmation, des noms de projets, ou même comme easter egg dans des logiciels et des jeux vidéo. Cela reflète la profonde impression laissée par l'œuvre de Adams sur les esprits créatifs et analytiques.
• Dans les débats philosophiques : Le chiffre 42, et par extension la question qu'il est censé répondre, a inspiré des débats philosophiques sur la recherche de sens, l'existence de vérités universelles et l'absurdité inhérente à l'existence humaine. Ces discussions touchent souvent à des concepts existentialistes et absurdistes, soulignant l'importance de créer son propre sens dans un univers indifférent.
Bien que le choix de 42 comme réponse à "la grande question sur la vie, l'univers et tout le reste" puisse avoir été arbitraire, son impact culturel et philosophique est indéniable. Douglas Adams a offert au monde un symbole puissant de la quête humaine de sens, enveloppé dans l'humour et l'absurdité. Que ce soit utilisé comme blague, citation inspirante, ou sujet de réflexion profonde, le chiffre 42 continue de captiver l'imagination et de stimuler la pensée, prouvant que parfois, une blague peut résonner bien au-delà de son intention originale. (ça me rappelle d'ailleurs la blague de Djamel du six-fois-sept-Karambeu)
Publié le par Technifree
En parler sur le forum
L'État fédéral allemand du Schleswig-Holstein abandonne Microsoft pour le logiciel libre : un pas vers la souveraineté numérique
Le gouvernement de l'État fédéral du Schleswig-Holstein, dans le nord de l'Allemagne, a récemment annoncé une transition majeure dans son infrastructure informatique. Après le succès d'un projet pilote, l'État a décidé de migrer 30 000 PC utilisés par l'administration locale de Microsoft Windows et Microsoft Office vers des solutions basées sur Linux, LibreOffice et d'autres logiciels libres et open source.
 Crédit image : GPT
Crédit image : GPT
Cette décision marque un tournant significatif vers ce que le ministre-président a décrit comme un « poste de travail informatique numériquement souverain ». En effet, le gouvernement du Schleswig-Holstein entend devenir une région pionnière en matière de numérique, avec une administration capable de contrôler ses propres solutions informatiques, tout en assurant la sécurité et la confidentialité des données des citoyens et des entreprises.
Le choix du logiciel libre s'inscrit dans une démarche de souveraineté numérique, un concept de plus en plus important à l'ère numérique où la dépendance à l'égard des fournisseurs de logiciels propriétaires peut compromettre la sécurité et l'indépendance des États.
L'utilisation de Microsoft 365 par la Commission européenne a également été remise en question récemment par le Contrôleur européen de la protection des données (CEPD), soulignant les préoccupations concernant la conformité avec la législation sur la protection des données.
Le ministre de la Transformation numérique, Dirk Schrödter, a souligné l'importance de cette transition non seulement en termes de sécurité des données, mais aussi en tant qu'opportunité de stimuler l'industrie locale et de créer des emplois en investissant dans des solutions informatiques locales.
La décision de passer à des logiciels libres et open source comme LibreOffice offre également des avantages économiques, en permettant aux administrations locales d'économiser sur les coûts de licence et en encourageant le développement de l'industrie du logiciel dans la région.
Cette transition, qui inclut également des initiatives telles que le passage à Linux comme système d'exploitation et l'adoption de solutions de collaboration open source, marque un engagement ferme en faveur de la souveraineté numérique et de l'autonomie technologique de l'État du Schleswig-Holstein.
En fin de compte, cette décision témoigne de la reconnaissance croissante du rôle crucial que jouent les logiciels libres et open source dans la préservation de la souveraineté et de la sécurité numériques, ainsi que dans la promotion de l'innovation et de la croissance économique locales.
Sources multiples :
schleswig-holstein.de
developpez.com
Publié le par Technifree
En parler sur le forum
Les efforts de Google pour lutter contre les fake news
À l'ère de l'information instantanée, démêler le vrai du faux est devenu une quête quotidienne pour de nombreux internautes. Le géant technologique Google, conscient de cet enjeu, a mis en place divers outils destinés à aider les utilisateurs à naviguer dans cet océan d'informations, parfois troubles. Ces initiatives, bien que louables, se heurtent toutefois à des limites quant à leur efficacité et leur accessibilité.
 Crédit image : Google
Crédit image : Google
Dans un contexte où le Forum économique mondial a identifié la désinformation comme l'un des plus grands risques pour l'humanité, Google a introduit plusieurs fonctionnalités pour faciliter la vérification des contenus en ligne. Parmi eux, l'outil "À propos de ce résultat", accessible en 40 langues, permet d'obtenir des informations sur la source d'une suggestion avant même de cliquer dessus. Une initiative similaire pour les images a également été lancée, permettant de vérifier le contexte d'une image affichée dans les résultats de recherche.
Le Fact Check Explorer, un moteur de recherche spécialisé dans les contenus de fact-checking, constitue une autre pierre angulaire de la stratégie de Google contre les fake news. Ce dernier offre aux journalistes et chercheurs un accès à plus de 150 000 contenus vérifiés par des éditeurs reconnus à travers le monde, leur permettant ainsi de repérer rapidement les affirmations déjà examinées par des médias.
Un bilan mitigé
Malgré ces efforts, l'efficacité de ces outils laisse à désirer selon certains critiques. Une étude de l'Université de Floride a révélé que, face à un millier de déclarations erronées sur la COVID-19, Google n'a pas réussi à fournir des informations de vérification des faits suffisantes dans la plupart des cas. Bien que les résultats proposés soient jugés relativement fiables, leur portée semble insuffisante pour endiguer la vague de désinformation.
De plus, l'observatoire français De Facto souligne un problème d'accessibilité et d'exhaustivité des informations vérifiées : elles ne sont pas suffisamment mises en avant dans les résultats de recherche ordinaires, rendant Fact Check Explorer un outil plus adapté aux professionnels du fact-checking qu'au grand public.
Vers un avenir plus éclairé ?
Google, via sa Google News Initiative, s'efforce de promouvoir une information de qualité en collaborant étroitement avec journalistes et éditeurs de presse. Si ces outils ne parviennent pas encore à éradiquer complètement la désinformation en ligne, ils constituent néanmoins une étape importante pour équiper les internautes et les professionnels d'outils de vérification efficaces. Les études montrent que la vérification des faits peut réduire la propagation de la désinformation sur les réseaux sociaux, soulignant l'importance de poursuivre et d'amplifier ces efforts.
Bien que les initiatives de Google pour lutter contre les fake news soient un pas dans la bonne direction, il reste encore un long chemin à parcourir pour garantir leur efficacité et leur accessibilité à tous. Dans cet environnement numérique en constante évolution, l'innovation et l'engagement continu seront cruciaux pour faire face aux défis de la désinformation.
Sources multiples :
FranceTVInfo
Wedig.fr
Google
Publié le par Technifree
En parler sur le forum
Espionner, mentir, détruire : plongée dans les arcanes de la cyberguerre
Le dernier ouvrage de Martin Untersinger, « Espionner, mentir, détruire, comment le cyberespace est devenu un champ de bataille », offre une plongée captivante dans les méandres de la cyberguerre contemporaine. En naviguant à travers les pages de cet exposé détaillé, le lecteur est confronté à une réalité complexe où les frontières entre espionnage, désinformation et sabotage sont devenues poreuses.
 Crédit image : Grasset
Crédit image : Grasset
L'auteur, journaliste au Monde, nous entraîne dans un voyage fascinant à travers les pratiques douteuses des États, qui se livrent une guerre sans merci dans le cyberespace. D'une manière remarquablement documentée, Untersinger dévoile les tactiques et les stratégies utilisées par les acteurs étatiques, révélant parfois des alliances surprenantes et des pratiques clandestines.
L'ouvrage met en lumière la dimension économique de la cyberguerre, où des sommes astronomiques sont dérobées chaque année à travers des opérations sophistiquées de cyberespionnage. Les entreprises françaises ne sont pas épargnées, subissant des attaques orchestrées principalement par des acteurs chinois. L'exemple d'Areva, dont la PDG a vu sa boîte e-mail exfiltrée pendant deux ans, met en évidence l'ampleur des pertes économiques subies.
Le livre explore également le marché florissant des logiciels malveillants, où même les États moins avancés technologiquement peuvent acquérir des outils de cyberespionnage sur le marché noir. Des logiciels comme Pegasus, développés par des entreprises privées comme NSO Group, sont utilisés par un éventail de pays pour surveiller leurs citoyens et leurs ennemis politiques.
En examinant le rôle croissant des entreprises privées dans le domaine du renseignement, l'ouvrage souligne les enjeux éthiques et politiques liés à la privatisation de la cyberguerre. Des sociétés travaillant étroitement avec les autorités américaines fournissent souvent des informations sensibles sur les attaques, mais leur partialité peut remettre en question la neutralité de leurs analyses.
Le livre aborde les défis complexes liés à l'attribution des cyberattaques, où les responsables sont souvent difficiles à identifier avec certitude. Des exemples comme l'attaque de TV5Monde en 2015, initialement revendiquée par l'État islamique mais finalement attribuée à la Russie, illustrent la complexité de ce domaine.
« Espionner, mentir, détruire » offre une analyse approfondie et éclairante de la cyberguerre contemporaine, mettant en lumière les enjeux cruciaux liés à la sécurité et à la souveraineté dans le cyberespace. Cet ouvrage captivant est un incontournable pour quiconque souhaite comprendre les défis et les dangers de cette nouvelle frontière de la guerre moderne.
Sources :
Challenges.fr
Publié le par Technifree
En parler sur le forum
