Vers une transparence renforcée pour l’IA open-source en France
L'Open Source Initiative (OSI), reconnue pour sa rigueur dans la définition de l’open source, a publié la version 1.0 de sa propre définition de l'IA open source. Inspirée des libertés du logiciel libre, cette définition fixe quatre principes fondamentaux :
• Liberté d’utilisation : tout utilisateur peut exploiter le modèle pour n'importe quel usage sans demande préalable. • Liberté d’examen : les utilisateurs peuvent étudier le modèle pour comprendre ses mécanismes et ses composants. • Liberté de modification : les utilisateurs peuvent modifier le modèle à des fins diverses, y compris pour altérer ses résultats. • Liberté de partage : les utilisateurs peuvent redistribuer le modèle, avec ou sans modifications, pour n’importe quel usage.
Ces libertés fondent la base de l’open source, mais elles ne sont pas obligatoirement toutes requises pour chaque projet d’IA. Cette ouverture a pour but de favoriser une accessibilité plus large tout en laissant aux concepteurs une marge de manœuvre pour imposer des restrictions selon leurs besoins spécifiques.
Le comparateur d'ouverture : L'outil du gouvernement pour mieux s’orienter
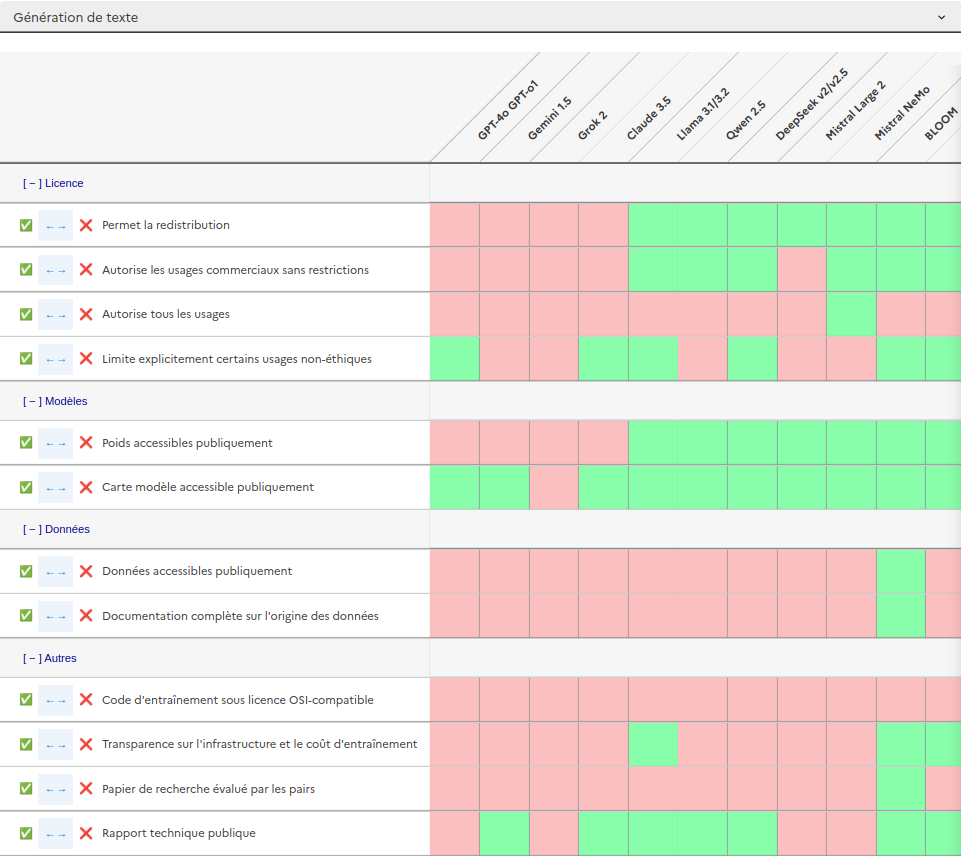
Face à la complexité croissante de l’IA, le gouvernement français, par le biais du PEReN, a récemment introduit un comparateur d’ouverture des modèles d’IA. Cet outil aide les utilisateurs à choisir des modèles de génération de texte ou d’image en fonction de critères d’ouverture spécifiques. Le comparateur regroupe actuellement 14 modèles textuels et 6 modèles visuels, et permet de trier selon divers facteurs tels que :
• La possibilité de redistribution du modèle • La licence d’usage commerciale • Les restrictions éthiques • La transparence sur les données d’entraînement et la documentation
Par exemple, un modèle comme BLOOM, bien que largement ouvert, impose certaines limitations d’usage. En revanche, Mistral offre une liberté d’utilisation totale, mais sans fournir de documentation complète sur ses données d’entraînement.
Un tableau évolutif et collaboratif
Conçu pour évoluer, le comparateur de PEReN se veut un outil collaboratif, encourageant les utilisateurs et experts à contribuer à son enrichissement. Les critères d’ouverture varient, intégrant des éléments comme la disponibilité des poids du modèle, la publication des articles scientifiques associés, et la transparence de l’infrastructure. Ce tableau est particulièrement utile pour quiconque cherche à évaluer le degré d’ouverture de différents modèles et choisir en fonction de ses besoins.
La gouvernance : un aspect fondamental du développement de l’IA
Au-delà des critères d’ouverture, la question de la gouvernance des modèles open source soulève des débats. Le PEReN met en garde contre les dérives possibles : un modèle open source peut être vulnérable à des pratiques de contrôle par des entreprises dominantes. Par exemple, Android, bien que considéré comme open source, reste sous la domination de Google qui contrôle en partie cet écosystème. Cette situation rappelle la nécessité de surveiller la gouvernance des projets open source dans le domaine de l'IA pour prévenir les dérives monopolistiques, telles qu'on peut le constater un peu partout (vive le capitalisme !).
La définition de l'OSI insiste désormais sur une transparence accrue concernant les données d’entraînement. Une simple description détaillée n'est plus suffisante : l’OSI exige désormais une présentation exhaustive des données utilisées, un point crucial pour garantir l'intégrité et l’éthique dans le développement des modèles. De plus, la méthodologie de filtrage des données doit être documentée et son code publié, une exigence qui marque une avancée vers une meilleure traçabilité des processus d’entraînement.
Une absence de contrainte sur la publication des paramètres du modèle
L’OSI ne souhaite pas pour l’instant imposer de licence spécifique pour la publication des paramètres du modèle. Cette question pourrait se clarifier avec le temps et l’évolution de la législation autour de l'IA open source. En attendant, l’OSI encourage les concepteurs à publier les paramètres de leurs modèles pour favoriser la reproductibilité et la confiance dans les résultats.
Chez Meta on propose un modèle divergent de l’open source
La définition de l’OSI suscite toutefois des tensions, notamment avec Meta, qui revendique le caractère open source de ses modèles LLaMA. Bien que la société affirme partager plusieurs points de vue de l’OSI, elle ne publie pas les données d’entraînement de ses modèles. Cette réticence pose la question de l’équilibre entre l’ouverture et le respect des exigences de transparence.
Malgré certaines divergences, cette nouvelle définition reçoit malgré tout l’adhésion des acteurs du milieu (non, rien à voir avec Frodon). Clément Delangue, PDG de Hugging Face, salue cette avancée comme un jalon important pour renforcer la transparence, en particulier sur les données d’entraînement, ce qui est essentiel pour une IA responsable.
Sommes nous face à une initiative pionnière vers une IA éthique et accessible ? L’avenir nous le dira, mais une chose est sûre : la transparence et l’ouverture sont désormais au cœur des préoccupations de l’écosystème de l’IA open source.
Sources multiples :
Commentaires (0)
Connectez-vous pour commenter.